
Qiyu Yang
EDA Analysis
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# load data and split off X and y
housing = pd.read_csv('input_data2/housing_train.csv')
housing.describe()
| v_MS_SubClass | v_Lot_Frontage | v_Lot_Area | v_Overall_Qual | v_Overall_Cond | v_Year_Built | v_Year_Remod/Add | v_Mas_Vnr_Area | v_BsmtFin_SF_1 | v_BsmtFin_SF_2 | ... | v_Wood_Deck_SF | v_Open_Porch_SF | v_Enclosed_Porch | v_3Ssn_Porch | v_Screen_Porch | v_Pool_Area | v_Misc_Val | v_Mo_Sold | v_Yr_Sold | v_SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1941.000000 | 1620.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1923.000000 | 1940.000000 | 1940.000000 | ... | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 | 1941.000000 |
| mean | 58.088614 | 69.301235 | 10284.770222 | 6.113344 | 5.568264 | 1971.321999 | 1984.073158 | 104.846074 | 436.986598 | 49.247938 | ... | 92.458011 | 49.157135 | 22.947965 | 2.249871 | 16.249871 | 3.386399 | 52.553838 | 6.431221 | 2006.998454 | 182033.238022 |
| std | 42.946015 | 23.978101 | 7832.295527 | 1.401594 | 1.087465 | 30.209933 | 20.837338 | 184.982611 | 457.815715 | 169.555232 | ... | 127.020523 | 70.296277 | 65.249307 | 22.416832 | 56.748086 | 43.695267 | 616.064459 | 2.745199 | 0.801736 | 80407.100395 |
| min | 20.000000 | 21.000000 | 1470.000000 | 1.000000 | 1.000000 | 1872.000000 | 1950.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 2006.000000 | 13100.000000 |
| 25% | 20.000000 | 58.000000 | 7420.000000 | 5.000000 | 5.000000 | 1953.000000 | 1965.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.000000 | 2006.000000 | 130000.000000 |
| 50% | 50.000000 | 68.000000 | 9450.000000 | 6.000000 | 5.000000 | 1973.000000 | 1993.000000 | 0.000000 | 361.500000 | 0.000000 | ... | 0.000000 | 28.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 6.000000 | 2007.000000 | 161900.000000 |
| 75% | 70.000000 | 80.000000 | 11631.000000 | 7.000000 | 6.000000 | 2001.000000 | 2004.000000 | 168.000000 | 735.250000 | 0.000000 | ... | 168.000000 | 72.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 8.000000 | 2008.000000 | 215000.000000 |
| max | 190.000000 | 313.000000 | 164660.000000 | 10.000000 | 9.000000 | 2008.000000 | 2009.000000 | 1600.000000 | 5644.000000 | 1474.000000 | ... | 1424.000000 | 742.000000 | 1012.000000 | 407.000000 | 576.000000 | 800.000000 | 17000.000000 | 12.000000 | 2008.000000 | 755000.000000 |
8 rows × 37 columns
correlation analysis – housing3
housing3 = housing
housing3 = housing3.fillna(housing3.mean())
y=housing['v_SalePrice']
C:\Users\Y1733\AppData\Local\Temp\ipykernel_4604\3885830147.py:2: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
housing3 = housing3.fillna(housing3.mean())
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
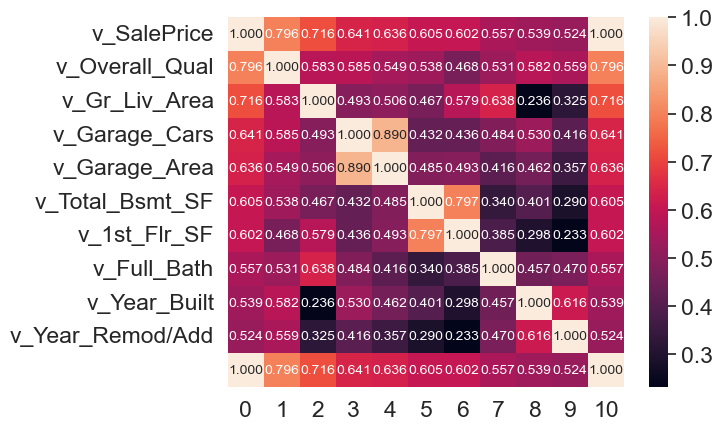
# calculate the correlation matrix
corr_matrix = housing3.corr()
# get the top k features that are most correlated with the target variable
k = 10
cols = corr_matrix.nlargest(k, 'v_SalePrice')['v_SalePrice'].index
# calculate the correlation coefficients between the top k features and the target variable
data = np.corrcoef(housing3[cols].values.T, y)
# create the heatmap
sns.set(font_scale=1.5)
hm = sns.heatmap(data, annot=True, fmt='.3f', annot_kws={'size':10}, yticklabels=cols.values)
plt.show()
Data pre-processing
- Drop outliers
housing.isnull().sum().sort_values(ascending=False) / housing.shape[0]
v_Pool_QC 0.993302
v_Misc_Feature 0.967543
v_Alley 0.929933
v_Fence 0.811953
v_Fireplace_Qu 0.484286
...
v_MS_SubClass 0.000000
v_Central_Air 0.000000
v_1st_Flr_SF 0.000000
v_2nd_Flr_SF 0.000000
v_SalePrice 0.000000
Length: 81, dtype: float64
#I will drop the data if it lost above 80%
housing.drop(columns=['v_Pool_QC','v_Misc_Feature','v_Alley','v_Fence'], axis=1, inplace=True)
# dropping outliers
be_dropped1 = list(housing[(housing['v_Lot_Area']>100000) & (housing['v_SalePrice']<400000)].index)
housing = housing.drop(index=be_dropped1)
be_dropped2 = list(housing[(housing['v_Garage_Area']>750) & (housing['v_SalePrice']>600000)].index)
housing = housing.drop(index=be_dropped2)
be_dropped3 = list(housing[(housing['v_Mas_Vnr_Area']>1000) & (housing['v_SalePrice']>600000)].index)
housing = housing.drop(index=be_dropped3)
be_dropped4 = list(housing[(housing['v_TotRms_AbvGrd']==10.0) & (housing['v_SalePrice']>700000)].index)
housing = housing.drop(index=be_dropped4)
be_dropped5 = list(housing[(housing['v_Garage_Yr_Blt']>1950) & (housing['v_SalePrice']>700000)].index)
housing = housing.drop(index=be_dropped5)
be_dropped6 = list(housing[(housing['v_Year_Built']<1950) & (housing['v_SalePrice']>300000)].index)
housing = housing.drop(index=be_dropped6)
be_dropped7 = list(housing[(housing['v_Year_Built']>1975) & (housing['v_SalePrice']>700000)].index)
housing = housing.drop(index=be_dropped7)
be_dropped8 = list(housing[(housing['v_Garage_Yr_Blt']>2050) & (housing['v_SalePrice']<300000)].index)
housing = housing.drop(index=be_dropped8)
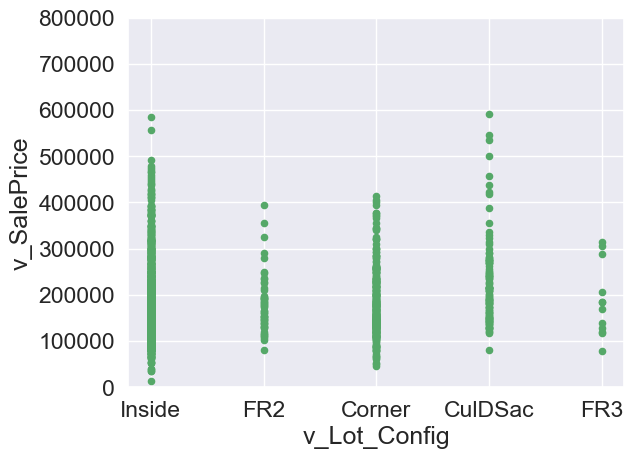
var = 'v_Lot_Config'
data = pd.concat([housing['v_SalePrice'],housing[var]],axis=1)
data.plot.scatter(x=var,y='v_SalePrice',ylim=(0,800000),color='g')
<AxesSubplot: xlabel='v_Lot_Config', ylabel='v_SalePrice'>
- check again
housing.isnull().sum().sort_values(ascending=False)
v_Fireplace_Qu 939
v_Lot_Frontage 316
v_Garage_Cond 107
v_Garage_Yr_Blt 107
v_Garage_Finish 107
...
v_MS_SubClass 0
v_Heating_QC 0
v_Central_Air 0
v_1st_Flr_SF 0
v_SalePrice 0
Length: 77, dtype: int64
housing4 – drop of v_SalePrice
# create test set for use later - notice the (random_state=rng)
housing4 = housing
y = np.log(housing.v_SalePrice)
rng = np.random.RandomState(0)
housing4 = housing.drop('v_SalePrice',axis=1)
X_train, X_test, y_train, y_test = train_test_split(housing4, y, random_state=rng)
from sklearn.pipeline import make_pipeline
from sklearn.compose import ColumnTransformer, make_column_selector
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.metrics import r2_score
from df_after_transform import df_after_transform
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LassoCV
from sklearn.model_selection import KFold, cross_validate, GridSearchCV
numer_pipe = make_pipeline(SimpleImputer(),
StandardScaler())
cat_pipe = make_pipeline(OneHotEncoder()) #handle_unknown='ignore'
preproc_pipe = ColumnTransformer(
[
# numerical vars
("num_impute", numer_pipe, make_column_selector(dtype_include=np.number)),
# categorical vars
("cat_trans", cat_pipe, ['v_Sale_Condition'])
]
, remainder = 'drop'
)
Model analysis
- Lasso
from sklearn.linear_model import Lasso
lasso_pipe = make_pipeline(preproc_pipe,
Lasso(alpha=.3))
score_alpha_0_3 = cross_validate(lasso_pipe,X_train,y_train,
cv=KFold(10), scoring='r2')['test_score'].mean().round(5)
search_alphas = list(np.linspace(0.001,0.007,7))+\
list(np.linspace(0.0072,0.0082,101))+\
list(np.linspace(0.0085,.02,20))+\
list(np.linspace(0.02,1,10))
parameters = [ {'lasso__alpha': search_alphas}]
# set up search grid
grid_search1 = GridSearchCV(estimator = lasso_pipe,
param_grid = parameters,
scoring = 'r2',
cv = KFold(10))
results1 = grid_search1.fit(X_train,y_train)
results2 = make_pipeline(preproc_pipe,LassoCV(cv = KFold(10)))
results2.fit(X_train,y_train)
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('num_impute',
Pipeline(steps=[('simpleimputer',
SimpleImputer()),
('standardscaler',
StandardScaler())]),
<sklearn.compose._column_transformer.make_column_selector object at 0x000001F2E6F4CE50>),
('cat_trans',
Pipeline(steps=[('onehotencoder',
OneHotEncoder())]),
['v_Sale_Condition'])])),
('lassocv',
LassoCV(cv=KFold(n_splits=10, random_state=None, shuffle=False)))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('num_impute',
Pipeline(steps=[('simpleimputer',
SimpleImputer()),
('standardscaler',
StandardScaler())]),
<sklearn.compose._column_transformer.make_column_selector object at 0x000001F2E6F4CE50>),
('cat_trans',
Pipeline(steps=[('onehotencoder',
OneHotEncoder())]),
['v_Sale_Condition'])])),
('lassocv',
LassoCV(cv=KFold(n_splits=10, random_state=None, shuffle=False)))])ColumnTransformer(transformers=[('num_impute',
Pipeline(steps=[('simpleimputer',
SimpleImputer()),
('standardscaler',
StandardScaler())]),
<sklearn.compose._column_transformer.make_column_selector object at 0x000001F2E6F4CE50>),
('cat_trans',
Pipeline(steps=[('onehotencoder',
OneHotEncoder())]),
['v_Sale_Condition'])])<sklearn.compose._column_transformer.make_column_selector object at 0x000001F2E6F4CE50>
SimpleImputer()
StandardScaler()
['v_Sale_Condition']
OneHotEncoder()
LassoCV(cv=KFold(n_splits=10, random_state=None, shuffle=False))
# score it on the test sample:
# lasso
y_test_predict1 = results1.predict(X_test)
test_score1 = r2_score(y_test,y_test_predict1)
#lassoCV
y_test_predict2 = results2.predict(X_test)
test_score2 = r2_score(y_test,y_test_predict2)
test_score1
0.8803684842772332
test_score2
0.88061843735059
- Ridge
from sklearn.linear_model import Ridge
ridge_pipe = make_pipeline(preproc_pipe,
Ridge(alpha=1))
score_alpha_1 = cross_validate(ridge_pipe, X_train, y_train,
cv=KFold(10), scoring='r2')['test_score'].mean().round(5)
search_alphas = list(np.linspace(0.001, 0.007, 7)) + \
list(np.linspace(0.0072, 0.0082, 101)) + \
list(np.linspace(0.0085, .02, 20)) + \
list(np.linspace(0.02, 1, 10))
parameters = [{'ridge__alpha': search_alphas}]
# set up search grid
grid_search3 = GridSearchCV(estimator=ridge_pipe,
param_grid=parameters,
scoring='r2',
cv=KFold(10))
results3 = grid_search3.fit(X_train, y_train)
y_test_predict3 = results3.predict(X_test)
test_score3 = r2_score(y_test,y_test_predict3)
print(test_score3)
0.8800217607880119
- RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
rf_pipe = make_pipeline(preproc_pipe,
RandomForestRegressor(n_estimators=100, max_depth=5))
score_rf = cross_validate(rf_pipe, X_train, y_train,
cv=KFold(10), scoring='r2')['test_score'].mean().round(5)
parameters = {'randomforestregressor__n_estimators': [50, 60, 70],
'randomforestregressor__max_depth': [1, 3, 5, 7]}
grid_search_rf = GridSearchCV(rf_pipe, parameters, cv=KFold(10), scoring='r2')
results4 = grid_search_rf.fit(X_train, y_train)
y_test_predict4 = results4.predict(X_test)
test_score4 = r2_score(y_test,y_test_predict4)
print(test_score4)
0.8721996173364622
- xgboost
# pip install xgboost
import xgboost as xgb
xgb_pipe = make_pipeline(preproc_pipe,
xgb.XGBRegressor(objective='reg:squarederror'))
score_xgb = cross_validate(xgb_pipe, X_train, y_train,
cv=KFold(10), scoring='r2')['test_score'].mean().round(5)
parameters = {'xgbregressor__max_depth': [3, 4, 5, 7],
'xgbregressor__learning_rate': [0.01, 0.1, 0.2],
'xgbregressor__n_estimators': [30, 50, 70, 100]}
grid_search_xgb = GridSearchCV(xgb_pipe, parameters, cv=KFold(10), scoring='r2')
results5 = grid_search_xgb.fit(X_train, y_train)
y_test_predict5 = results5.predict(X_test)
test_score5 = r2_score(y_test,y_test_predict5)
print(test_score5)
0.9071539386544836
print(results5.best_params_)
{'xgbregressor__learning_rate': 0.1, 'xgbregressor__max_depth': 3, 'xgbregressor__n_estimators': 100}
- lightgbm
# pip install lightgbm
import lightgbm as lgb
lgb_pipe = make_pipeline(preproc_pipe,
lgb.LGBMRegressor(objective='regression'))
score_lgb = cross_validate(lgb_pipe, X_train, y_train,
cv=KFold(10), scoring='r2')['test_score'].mean().round(5)
parameters = {'lgbmregressor__max_depth': [3, 5, 7],
'lgbmregressor__learning_rate': [0.01, 0.1, 0.3],
'lgbmregressor__n_estimators': [30, 50, 70, 90]}
grid_search_lgb = GridSearchCV(lgb_pipe, parameters, cv=KFold(10), scoring='r2')
results6 = grid_search_lgb.fit(X_train, y_train)
y_test_predict6 = results6.predict(X_test)
test_score6 = r2_score(y_test,y_test_predict6)
print(test_score6)
print(results6.best_params_)
0.900525593546391
{'lgbmregressor__learning_rate': 0.1, 'lgbmregressor__max_depth': 7, 'lgbmregressor__n_estimators': 90}
test the holdout
holdout = pd.read_csv("input_data2/housing_holdout.csv")
holdout['v_SalePrice'] = 0
y_pred = results5.predict(holdout)
# Get the ID values for the test data
parcel = holdout['parcel'].values
# Combine the predicted values and ID values into a single DataFrame
predictions = pd.DataFrame({'parecel': parcel, 'v_SalePrice': y_pred})
# Save the predictions to a CSV file
predictions.to_csv('submission/MY_PREDICTIONS.csv', index=False)